


How Far Are We From Being Able to Generate Whatever 3D Objects On the Fly?
I'll Keep This Short


Welcome to my bi-weekly newsletter, “I’ll Keep This Short,” where I navigate the less-traveled paths of AI, building new insight beyond the banal, mainstream chatter.
Step Into a New Dimension
Walking across your living room floor, coffee in hand, you ready yourself to sit down in your nice, relaxing avocado-shaped easy chair for some well-earned rest after a hard day’s work of writing prompts and generating images.

Dalle-2 Prompt: “3d render of a chair that looks like an avocado digital art”
While you sit there drinking your very real coffee, staring off into space, probably what you don’t think to yourself is, “Whew, I sure am glad that this chair in fact exists in physical reality.”
But in fact that’s precisely where we’re at with the vast majority of AI-generated content on the internet today. We’re a heck of a long way off from creating actual 3D content on the fly. Even the avocado chair above, while it certainly looks 3-dimensional, it’s really a 2-dimensional rendering trained on previous 2-dimensional snapshots of 3D renders that a human did.
For those who have used 3D modeling software it’s likely imminently clear what I am talking about. 3D CAD software has been ubiquitous since the 1980’s as something used to model virtually everything, from furniture here on earth to furniture on the International Space Station.

Since I’m not clear on how familiar the vast majority of everyone reading this article might on the nuances of 3D objects vs. 3D pictures in 2D space, I drew a little demonstration to show what I mean when I am talking about the difference between illusory 3D objects and real 3D objects below.
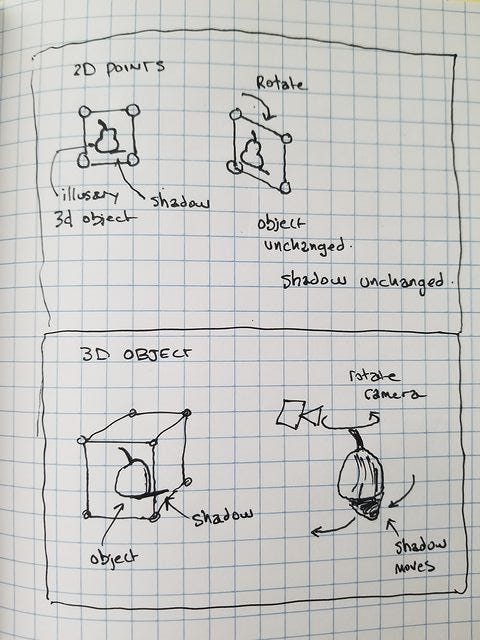
If you rotate a 3D object, you should be able to see the other side of it, in some kind of software environment. If you rotate a picture of a 3D object, an illusory 3D object, you will see the other side of the picture frame, and the illusory object does not change.
So where the heck are we as a species in terms of being able to generate some sweet, sweet, real 3D objects? There’s got to be tons of uses for text-generative 3D objects, from being able to generate and 3D-print out your own personal toe-door-opener things you see in bars, to a plastic bust of Karl Marx that fits over the end of your toothpaste tubes, so that Karl Marx can spit toothpaste on to your brush every night.
What Peak Performance Looks Like
This is what peak 3-dimensional performance looks like. You may not like it, but this is actually the first actual 3D printed object that was created using mathematics - the Utah Teapot, first rendered in 1975 by a researcher at the University of Utah.

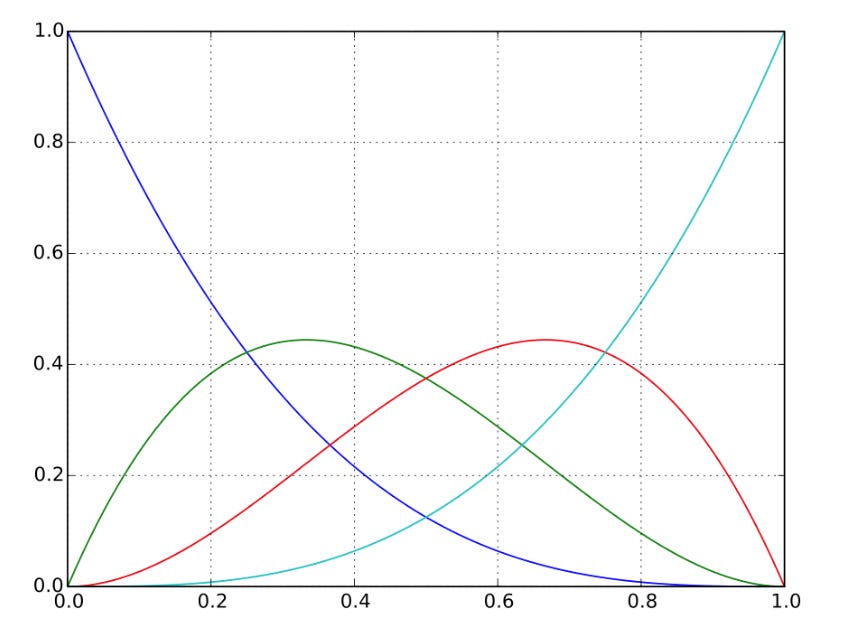
Short and stout, with a handle and a spout, when you tip it over, you realize it’s actually rendered via Bézier Curves rather than just perhaps a bunch of points manually configured by hand in a grid space. Bézier Curves are essentially parabolic lines defined by mathematical functions, like these. You can imagine how a congruence of several of these in a defined way can be used to create objets.
Let’s contrast this to an illusory 3D avocado teapot, as interpreted by Dall-E 2, just for kicks:

While cool, it’s a hallucination, without any real physical embodiment, that is to say, there isn’t really a 3D point cloud which dictates how those shadows fall and how that light bounces off of the surface. There would be no way to, “rotate” these on the screen, they are purely illusory 3D objects, not, “real 3D objects.”
The above gives us a foundational understanding for where 3D graphics came from in the first place. So how about generative 3D objects?
Enter Shap-E
Perhaps you’ve heard about Dall-E, how about Shap-E? Recently, a paper came out from OpenAI researches called Shap-E, which is a 3D object generator. From the paper, Shap-E is an improvement over a previous model called Point-E. Whereas Point-E modeled point clouds, Shap-E uses something called Neural Radiance Fields (NeRF) which represents a scene as an implicit function. Never mind what NeRF is for a moment.
What you get as a result of NeRF in contrast to Point Clouds is something like this:

As opposed to Point Cloud images which are very detailed like the following, but are lacking in realistic surface interpretation:

So here's the tricky part. While this does seem to be an interesting approach, the value of Dall-E and other generative AI seems to be in part the capability to create, "whatever," but you don't seem to be able to do that with Shap-E, it creates all sorts of mistakes, e.g.:.
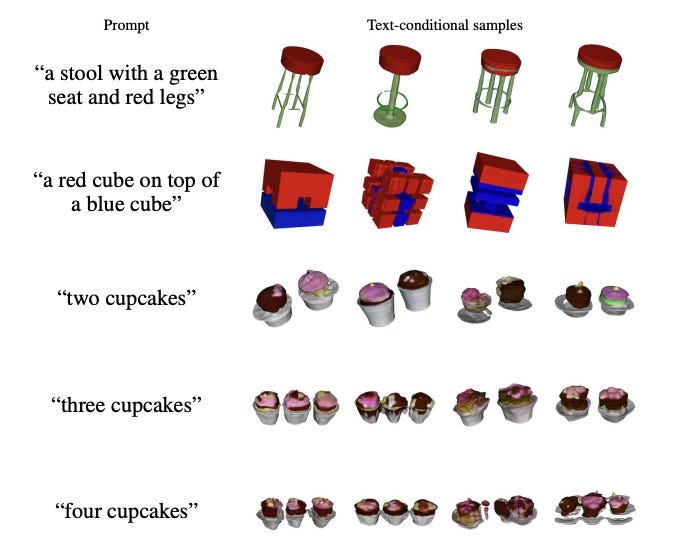
The resulting samples also seem to look rough or lack fine details, or outright hallucination in the form of not being what was requested.
Further, this is not covered in the paper, but the architecture seems to be super resource heavy as far as I can tell, I tried to run it in a Colab notebook and it took forever, so this might not be, "cheap." I’ll go over this in the next section.
My Attempt At Running Shap-E in a Colab Notebook
I was able to render an image of a dog with a HuggingFace demo:

Ran the model with a prompt:
Note that the notebook needed to be set to GPU runtime mode under, “edit” in order to work in faster order. If you set the runtime to GPU, it works within seconds if not less than a minute under minimal settings, which is pretty fast.
…and I was able to successfully convert this into a GLTF file, which looks like the following (although the below was created in HuggingFace, not Colab):
The HuggingFace generative model also works within under a minute.

Mathematical Background
Point-E Math
So Shap-E the 3D object generator paper shows an improvement over a that previous Point-E model. Whereas Point-E modeled point clouds, Shap-E uses that Neural Radiance Fields or NeRF process we talked about earlier. Let’s go a bit deeper into what NeRF is.
First off some basic definitions. An implicit function is a mathematical function that involves variables implicitly, as opposed to explicitly having a relationship, as is the case in an explicit function. Where in this function:
yis explicitly a function of x. Whereas in the function:
x and y have an implicit relationship. If x moves, then y is going to move as well.
Point-E used an explicit generative model over point clouds to generate 3D assets, unlike Shap-E which directly generates the parameters of implicit functions. So in rendering a 3D object, Point-E uses a Gaussian Diffusion process was used to mimic how a light source illuminates a scene.
Noising Process:
:= signifies that the above is a definition. The function q is what we are defining here, and N signifies the noise process occurring.
the state xt at time t is generated from the state xt−1 at the previous time step, so basically this shows that we’re doing something at subsequent steps in time, going back and operating on a thing we just operated on.
The state xt is a noisy version of xt−1, where the noise is Gaussian with mean sqrt(1−βt*x(t−1)) and covariance βtI. The parameter βt determines the amount of noise added at each time step.
Where:
where ϵ is a Gaussian random variable which explicitly defines xt, and αˉt is a noise parameter βt up to time t.
So in other words, xt can be thought of as a natural, bell-curve like process, it’s randomized by this ϵ thing which generates values along a bell curve.
You can think of light bouncing off of a smooth (Gaussian) surface as a totally natural, generative act that follows a bell curve. If the surface is smooth or not really too skewed in one way or another, then the light is going to bounce off it in a smooth fashion.
Point-E Result
So as a result, Point-E was able to generate images which are very detailed like the following Avocado chair:

Shape-E Math
So with that being said, what Shap-E did is reversed the above Noising Process, q(xt−1∣xt), using a neural network, pθ(xt−1∣xt), setting the goal of learning the paremeters θ of the neural network so that it can accurately reverse the noising process.
Contrast this to Shap-E, which implicitly maps an input pair with :
The given equation, Neural Radiance Field (NeRF), defines a function FΘ that maps an input pair (x,d) to an output pair (c,σ).
x is a 3D spatial coordinate. This could represent a point in a 3D scene or a 3D model.
d is a 3D viewing direction. This could represent the direction from which x is being viewed, such as the direction from a camera to x.
c is an RGB color. This is the color that the function computes for the point x when viewed from the direction d.
σ is a non-negative density value. This could represent the density of a volume at the point x, which could affect how light interacts with the point and thus influence the computed color.
The function FΘ takes a spatial coordinate and a viewing direction as input and computes a color and a density as output. The exact way in which it computes the color and density would be determined by the parameters Θ. So with that mathematical background understood, Shap-E was trained in two stages:
An encoder was trained to map a bunch of 3D assets into the parameters of this above implicit function (as well as another one which I won't go into here) which takes viewing direction as input and color and density as output.
A Conditional Diffusion Model was trained on the outputs of the encoder. A Conditional Diffusion Model is like a Guassian Diffusion Model used in PointE above, but conditioned on text-based descriptions of the original training images.
So to try to put this in more understandable terms, just imagine a tiny painter sitting in a 3D axis centered in the middle of a room, with a light overhead. They have an extendible arm with a paintbrush on the end, and it’s magical paint that can be suspended in the air. Basically, they pivot their direction and look up and down, painting an objet, “around them,” by depositing paint of an appropriate color based upon the angle they are painting at. If there is more of a shadow, they paint a bit darker color, if it’s brighter, they paint brighter.
The result of this tiny magic, extendible arm artist with floating paint is a very coherent, smooth object created based upon how light and shadows fell on other objects of a similar type.
Shap-E Result
Shap-E was able to generate images which were, "pleasing," “smooth,” and did not skip out on parts of the model as opposed to Point-E, like the following:

So here's the tricky part. While this does seem to be an interesting approach, the value of Dall-E and other generative AI seems to be in part the capability to create, "whatever," but you don't seem to be able to do that with Shap-E, it creates all sorts of mistakes.
What About Just Rendering with Code with a Large Language Model?
As I have mentioned in a previous post, large language models have a problem with factual knowledge alignment, and this goes in particular for more specific, niche topics.
We can observe that the best of class, GPT-4 LLM as of May 2023 does not deliver even the simplest everyday object:
Create a house in OpenScad
Imagine trying to build an actual house with this technology. Gah! What happened to my roof? I appreciate that my car is dry but really it would have been much better to protect my living room.
There’s a Market for That
So of course I set up a betting market on Manifold, my favorite Predictions Marketplace, to try to get an idea of where this will go.
As of the time of writing, this is sitting at about 65%, but you can check the new probability below or by following the link to the market itself.
I will not bet on this market, but I will have to figure out a way to resolve it, which may become contentious if there is a large trader volume by the time it needs to be resolved, prior to June, 2024.
Bonus Material: Not Included on LinkedIn Newsletter
Since authoring this above article, there has been at least one startup that I have come across which generates 3D images with prompts, 3DFY. While their promise is, “3D Everything Now,” they seem to be running in a much more limited beta version, where they heavily restrict the types of objects that can be created, in favor of quality.

Their business model or prototype for now at least seems to be geared toward generating objects that can actually be used in a gaming or modeling environment. They allow you to pick from a set number of objects to start with, so perhaps this could be considered either a, “mixed model,” or a heavily restricted generative model.
In the interests of just checking this out to see what kind of outputs the model really comes out with, I tried out a couple avocado-themed items:

There was no, “chair,” option, but we could use sofa as a base object:
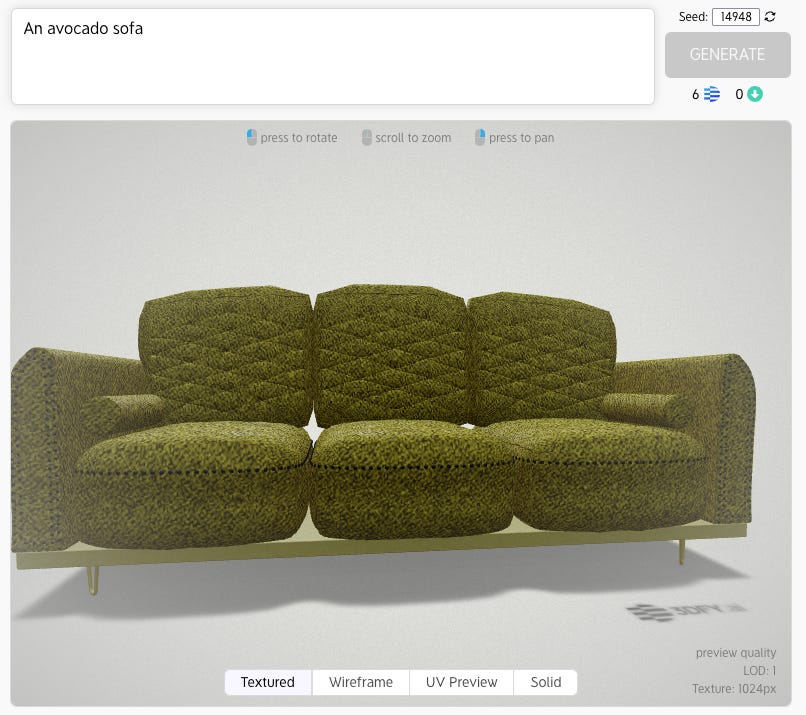
So while the models look great, there wasn’t really a lot of flexibility or creativity. The models appear to be conservative, geared toward making an actual quality output rather than a highly creative object. The couch above appears to take inspiration from an avocado color rather than an object.